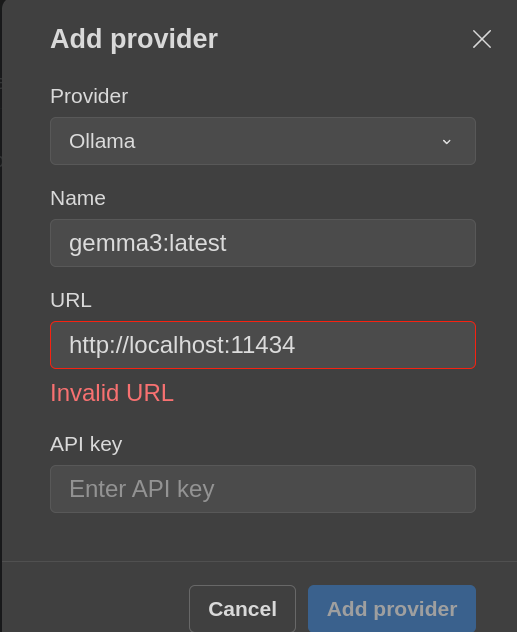
Thanks @Constantine . The code was just observation that localhost seems hardcoded.
==Setup Clarified==
Linux Machine A = Ollama machine running Ollama directly (NOT as a Docker) (machine not used much and a backup)
Linux Machine B = Ollama machine running Ollama via Docker instance
Both servers run ollama. Each is assigned a locally-routable IP. I include both because this might be what is causing confusion. It really doesn’t matter which. Both are accessible via the network. These are server machines running local ollama instances and used for AI stuff.
Linux Machine C = Desktop Editors installed (a daily use laptop) <–THIS IS USED TO RUN ONLYOFFICE DESKTOP
== Curl Results ==
Curl shows both ollama instances are fully available via the network.
I run curl on all three machines.
I run curl on Machine A. curl http://192.168.222.170:11434/api/tags This returns something like {"models":[{"name":"codellama:13b","model":"codellama:13b","modified_at":"2025- ... SNIP
I run curl on Machine B. curl http://192.168.222.171:11434/api/tags This returns something like {"models":[{"name":"nomic-embed-text:latest","model":"nomic-embed-text:latest", ... SNIP
I run curl on Machine C. There is no local instance of Ollama so no results.
I run the same curl statements above from Machine C and all return exactly the same information as posted above.
I hope that clarifies.
==Summary (not complaint, just observation from my perspective)==
- the AI Plugin only seems to handle same-machine,
localhost instances of Ollama (with localhost hard coded)
- I do not see any alternatives in the code such as reading an
ENV variable (such as reading OLLAMA_HOST) to override the default, hard coded localhost (and this may be risky but seems suggested by prior comments about setting ENV variables)
- I just observe that the constructors seem to affirm that only
localhost as the hard-coded text localhost is accommodated right now
==Use-case==
Yet, one of the reasons to run ollama as a provider is the ability to run ollama on a machine and allow me to acccess ollama no matter which laptop I use. So I can setup a headless server dedicated to AI and access it for my use.
This use-case will likely become more common as memory, GPU, and disk drive costs continue to shockingly escalated–I can no longer afford to store ollama instances, with all their AI-models, on every system or to add a GPU card to every system to run ollama.
I am going to complicate more but…the posed use-case illustrates the limits. Even if I temporarily run an ollama instance on the laptop so as to use Desktop Editors and the current AI Plugin, the token-count for any reasonable usage exceeds/impairs the entire resources Machine C (the laptop). See my point? The use of AI in Desktop Editors is fairly intensive and not workable for me (due to disk space, GPU limits, and memory limits) on my laptop. Thus, the headless server as Machine B (and an older A) which off-loads this intensive product. Example: Say I use Desktop Editors and the AI plugin to summarize a two-page memo. This is over 500 words (and many more tokens) sent to the ollama instance and a fairly intensive work-load for a simple laptop.